There are 3 main types of pipelines for the projects we and the industry run.
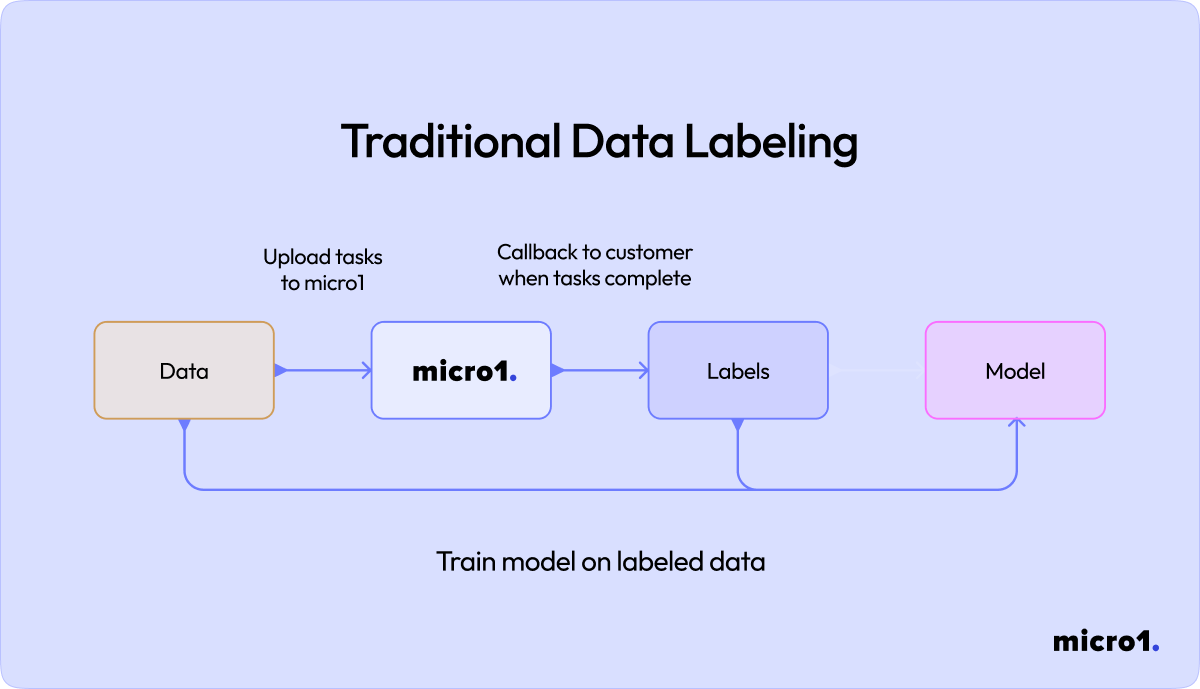
The first kind is a traditional data labeling pipeline, where a research team supplies a batch of data split into tasks to a data vendor. The data vendor would have experts label the data and once the project concludes, they would give the corresponding labels back to the research team as a deliverable. This doesn’t require the research team’s AI model to be online during the annotation stage, it is only necessary to run inference while generating the data (common the responses in prompt-response pairs).
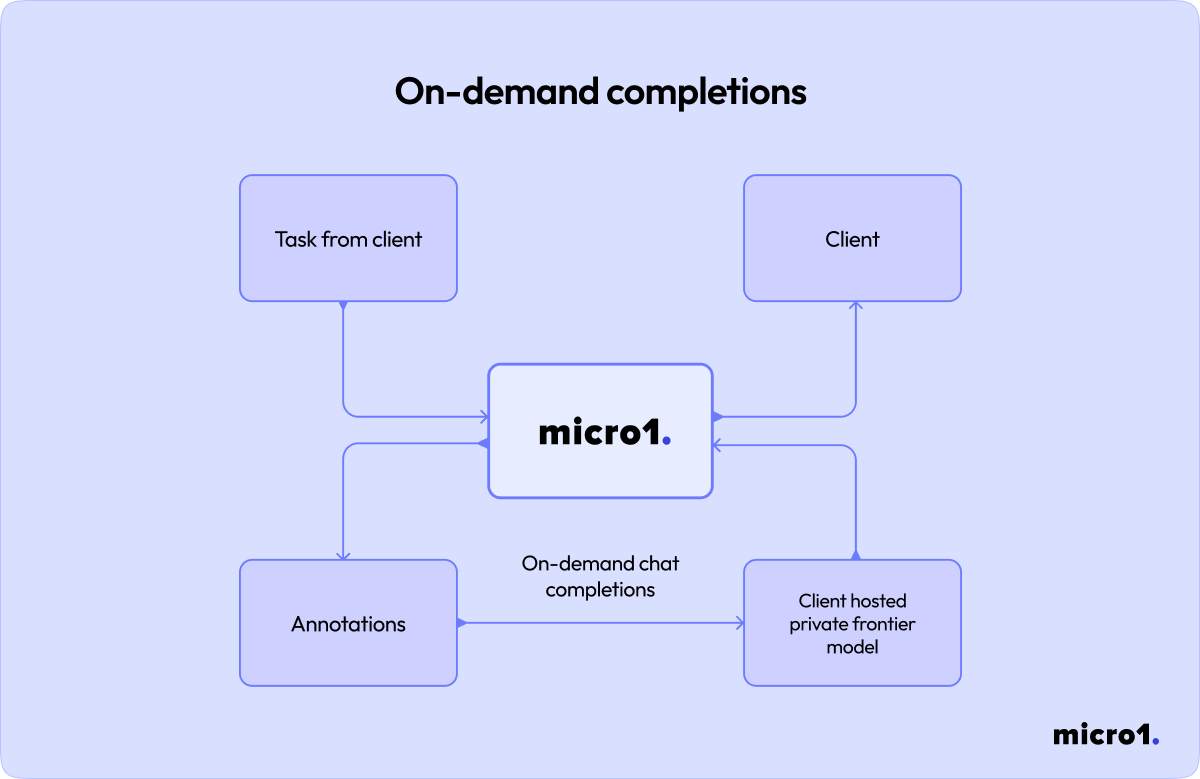
The second kind are on-demand completions, which requires the research team to keep the model online for inference anytime it might be needed. This has more costs for the research team, but it enables new types of human data to be generated. In the prior pipeline, experts can only label data, but in this type of pipeline experts can interact with the model.Let’s go into an example. Let’s imagine you are working with a large online storefront and are training a model to interact with customer requests over chat. Whenever a customer hits the feedback button in the chat, a copy of the chat is stored and the chatlog would be turned into a task and uploaded for inclusion in the project. There have been multiple reported incidents of the chatbot veering off-topic and helping answer math problems rather than answer questions about products or your storefront, as such, you applied a new SFT dataset to fine-tune your model, and now need human data to verify the efficacy of the fix. You could instruct experts to view a copy of the chat conversation and to try to replicate the undesirable behavior by entering the same thing as the customer. In case the conversation goes well, you could instruct experts to try to change one of the customer responses to try to trick the AI model into veering offtopic again. Either way, they would apply the proper annotations to both conversations so you can later fine-tune the AI model. This type of project would require the AI model to be online and accessible by the annotation team, which does come with operational overhead, but it would result in much more impactful data.
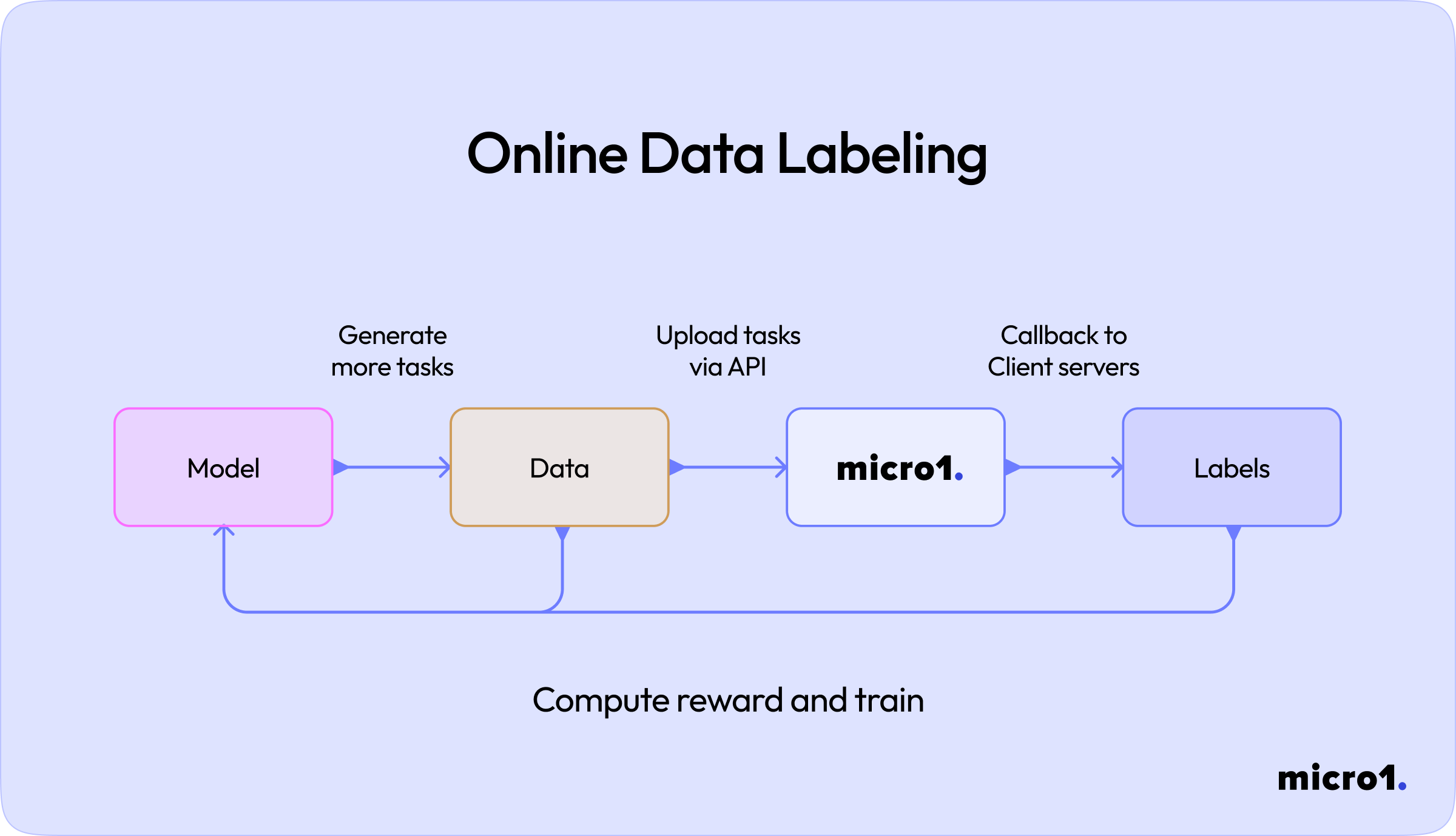
The third and final example of a pipeline is one with online data labeling. You continuously generate tasks from the current version of your model, either by having the model produce new prompts for experts to respond to or by sampling real user interactions, then feed these tasks into an annotation queue. Once experts complete their work, their labeled data can be immediately fed back into the model training process (e.g., for RLHF). This feedback loop lets you measure how each batch of labeled examples impacts the model’s performance and rapidly iterate on problem areas. While it requires orchestration between your data sources, annotation operations, and model hosting—and can incur higher engineering overhead—this approach is invaluable for large-scale, evolving products or research efforts where you need the freshest data and the fastest feedback cycles.